【交汇点新闻12月5日】在文字语言信息的海洋中,一种新的数据增强和训练策略或许可以让人工智能更聪明。近日,九尾狐狸m多媒体教室音箱2020级本科生时世骏以第一作者身份在《信息处理与管理》(中科院一区,IF=8.6)发表题为“使用基于数据增强和L2正则化的提示学习进行鲁棒的科学文本分类”的学术论文,,该期刊是Elsevier出版社旗下信息科学领域的权威期刊之一。九尾狐狸m多媒体教室音箱胡凯副教授为该文通讯作者。

图1:论文摘要
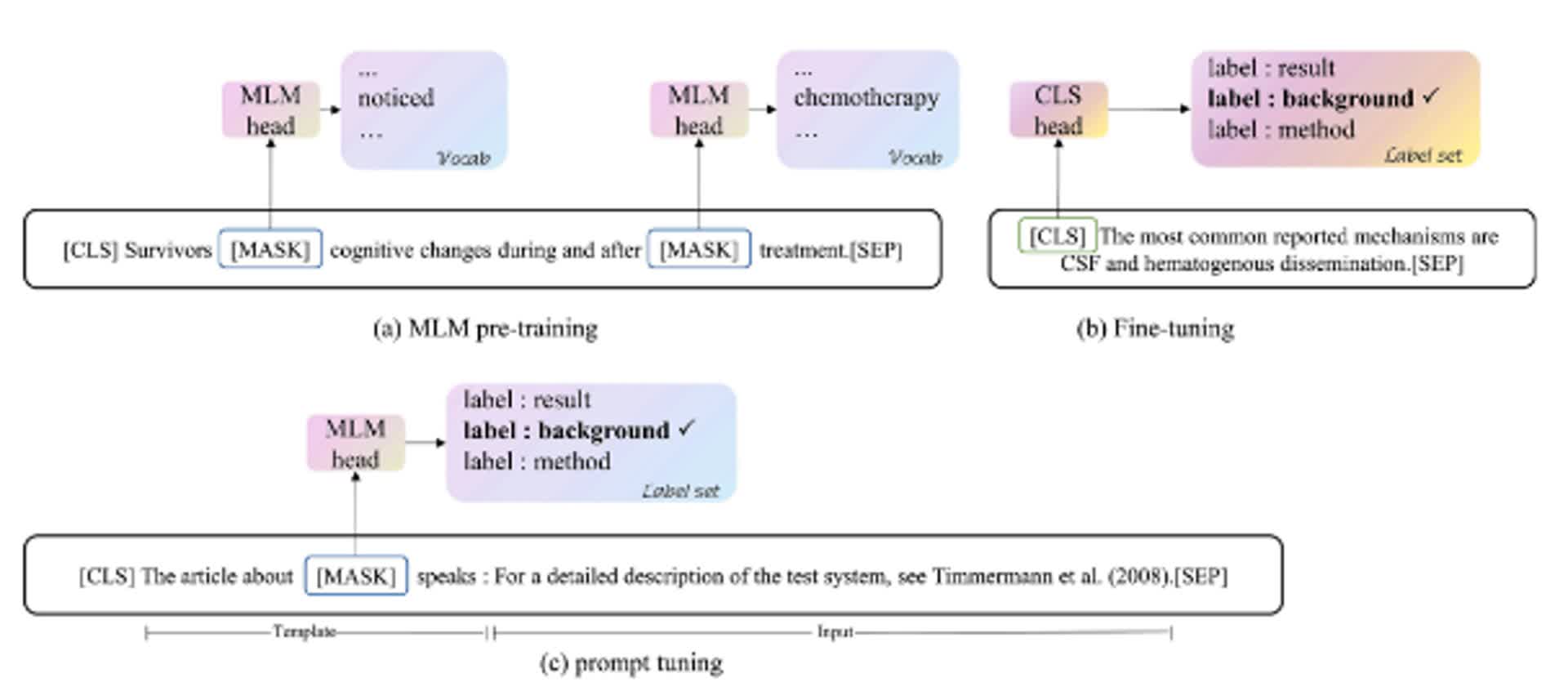
图2:掩码语言模型(MLM)预训练(a)、BERT模型的微调(b)和提示学习方法(c)
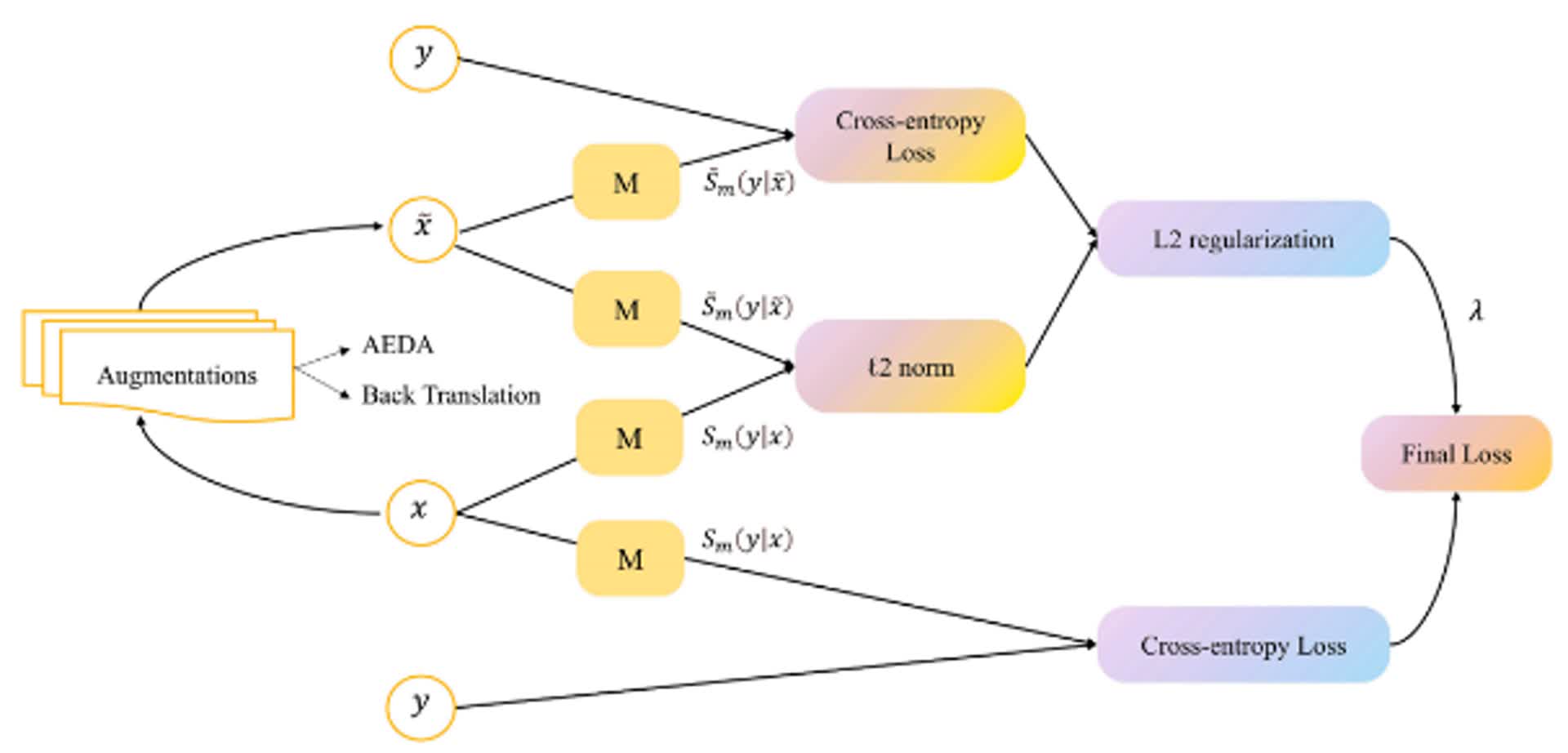
图3. 成对增强(L2正则化)策略loss函数设计
在ChatGPT及其相关技术大热的背景下,时世骏发现,在众多领域,如科学探索、专利分析和学术文献审查等,一个普遍的挑战是标注数据的稀缺性。人工智能在处理这类文本时,往往面临数据标注量小、新的术语层出不穷、词语过于专业等问题,给自动处理和分类带来了不小的困难。现阶段,这些领域的文本往往含有高度专业化的内容,其准确标注需要专家级知识和大量时间,既费力又成本高。如何解决这一问题呢,时世骏设计了一种新的数据增强和训练的策略。
“这就比如说,我们在教孩子识字时,他们能够快速分别出中文汉字和英文字母有很大差别,但是对于‘己’‘已’和‘人’‘入’这种‘看上去’差别不大的汉字来说,可能会容易出错。” 时世骏解释,“而通过我们的方法,我们让模型学习聚焦在这种细小的差异上,我们既让人工智能模型可以更高效地学习到知识处理准确的信息,也能够让他们更好处理科研生活应用场景中人类新创造出来的术语等少标注的数据。”
时世骏的研究不仅提高了模型的整体性能,还大幅减少了对大量标注数据的依赖,从而在资源有限的情况下,为研究和应用提供了新的可能性。
原文链接:https://jhd.xhby.net/share-webui/detail/s656efe4fe4b06569fa93b01f



